这同样也是一个备受争议的玩意。尤其是它还和Nepomuk搅到一起,让很多人更加不满意。
先说说它是个什么东西。简单说来就是一个个人信息管理框架,名称象征迦南神话中代表公正的预言女神。它的目标是实现一个跨桌面的个人信息管理的框架。可以参见下图:
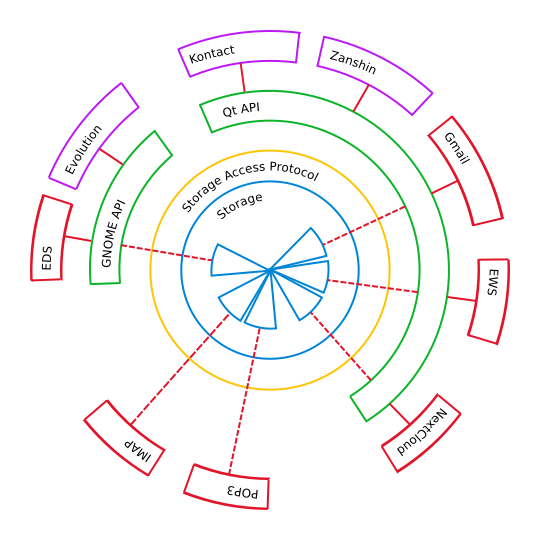
什么,你没有看错,计划里面是有Gnome的,虽然我并不清楚Gnome方面是完全没有动作呢还是怎么样。这个东西的目的就是将这些个人信息管理的数据和上层的应用分开,比如邮件管理,没有必要每个邮件程序都去搞一套POP3或者IMAP接受,只要从一个地方获得数据就好。甚至考虑到这个数据源可能不在你的电脑上,那么无论是你在公司的Gnome,抑或是笔记本上的KDE(举例而已),都可以享受到同样的数据服务。
同时在Web Application如此泛滥的年代,它同时也可以起到整合各个数据源的功能,比如日历,你可以使用远程文件,也可以使用本地文件,以及其他各个日历服务。甚至作为微博客的数据端(我看到现在已经支持这个功能了,但还没有测试过)。
他获得争议主要有以下几大原因,使用Nepomuk,后台进程,使用Mysql,以及早期bug繁多(这也是没办法)
早期来说这个实现还并不成熟(KDE 4.4时期),现在(KDE 4.6)已经变得更加成熟了一些。
为什么使用MySQL,这点的理由其实和Amarok的开发者很类似(原文,翻译),对于很多人喜欢的SQLite,他们的理由是无法支持高并发的访问。为什么没有和Amarok一样使用MySQL的嵌入模式,这是因为它无法支持InnoDB(MySQL的一个存储引擎,支持事务)。当然,和Amarok略有不同的一点是他还支持PostgreSQL作为存储引擎。
为什么需要Nepomuk?[1][5]
他们需要对虚拟文件夹进行快速的搜索和管理,Kmail自己的实现对于大量的文件来说已经不够了,而Nepomuk正好满足了他们的需求。同时,Nepomuk也可以提供有效的元数据查询服务。
关于资源的占用方面,我想大概这就是一个Trade off的问题,尤其是在硬件条件已经发展的情况下,不过话说回来,我运行很久KDE 4.6之后,同时Kmail也开关过几次。把所有程序都关闭(firefox之类)只剩桌面之后占用资源也不算很多。考虑到我的笔记本是4年前的纯种联想笔记本的话,其实我觉得没什么大不了的。
对于希望使用轻量级桌面的人来说,我觉得某种程度上需要做出取舍,自然,有Xfce,LXDE这样优秀的轻量级桌面供你使用,同样的如果你选择了KDE的话,那么你可能还是期望着更好的桌面体验,不是吗?(除非是它占用了不该占用的资源,那么你应该去汇报bug,:) )
对于用户来说,可以利用Akonadi达成平滑的跨桌面的个人信息管理体验。对于开发者来说,则可以利用各种各样的现有资源实现自己的应用。我个人喜欢KDE的一个原因就是我总是能在他上面体会到各种各样的新鲜的技术。
从目前Akonadi已经具有的功能和KDE现有的应用来说,我能想到很多有趣的玩法。KDE总体来说给我感觉是非常Web友好的,从Get New Stuff和openDesktop的集成来看,从Plasma对Google Gadget的支持来看,从Akonadi的后端也有很多Web资源(网络下载ical文件,日历支持blog,微博后端等)来看,我觉得在Web App发展到极致之前(比如Chrome OS真的能以不变应万变,虽然这在什么时候能够实现也未可知),KDE肯定是一个很好的选择,不过到那时KDE会发展成什么样呢(其实我很期待KDE占领移动平台,从我第一次看到手机上跑起来的Plasma就开始期待了) ?同样也是异常值得期待的。
资料来源:
5 FEEDBACKS